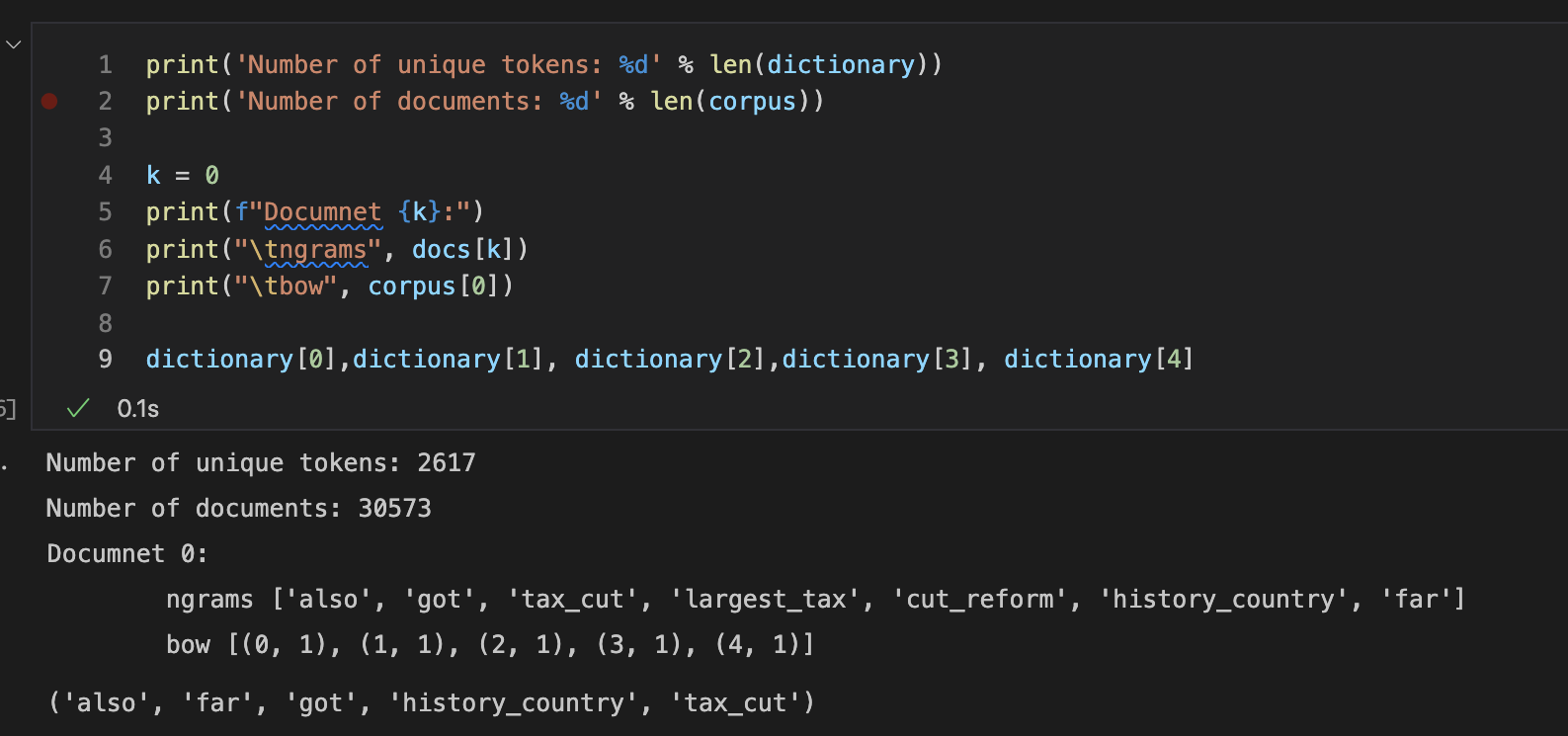
Now that we have cleaned, tokenised and generated ngrams for our documents (claims), we are ready to perform topic modelling
First we import the required modules
1 2 3 4 | |
and extract the documents that we wish to use in our model. Here I am using all rows/documents since I only have 30K and the resulting training only takes 3 minutes. For a larger dataset I would take a sample.
1 | |
Before training a topic model we need to perform some additional processing:
dictionary collection by accessing one of its keys.dictionary)1 2 3 4 5 6 7 8 9 | |
The collections dictionary and corpus can be inspected using usual python code:
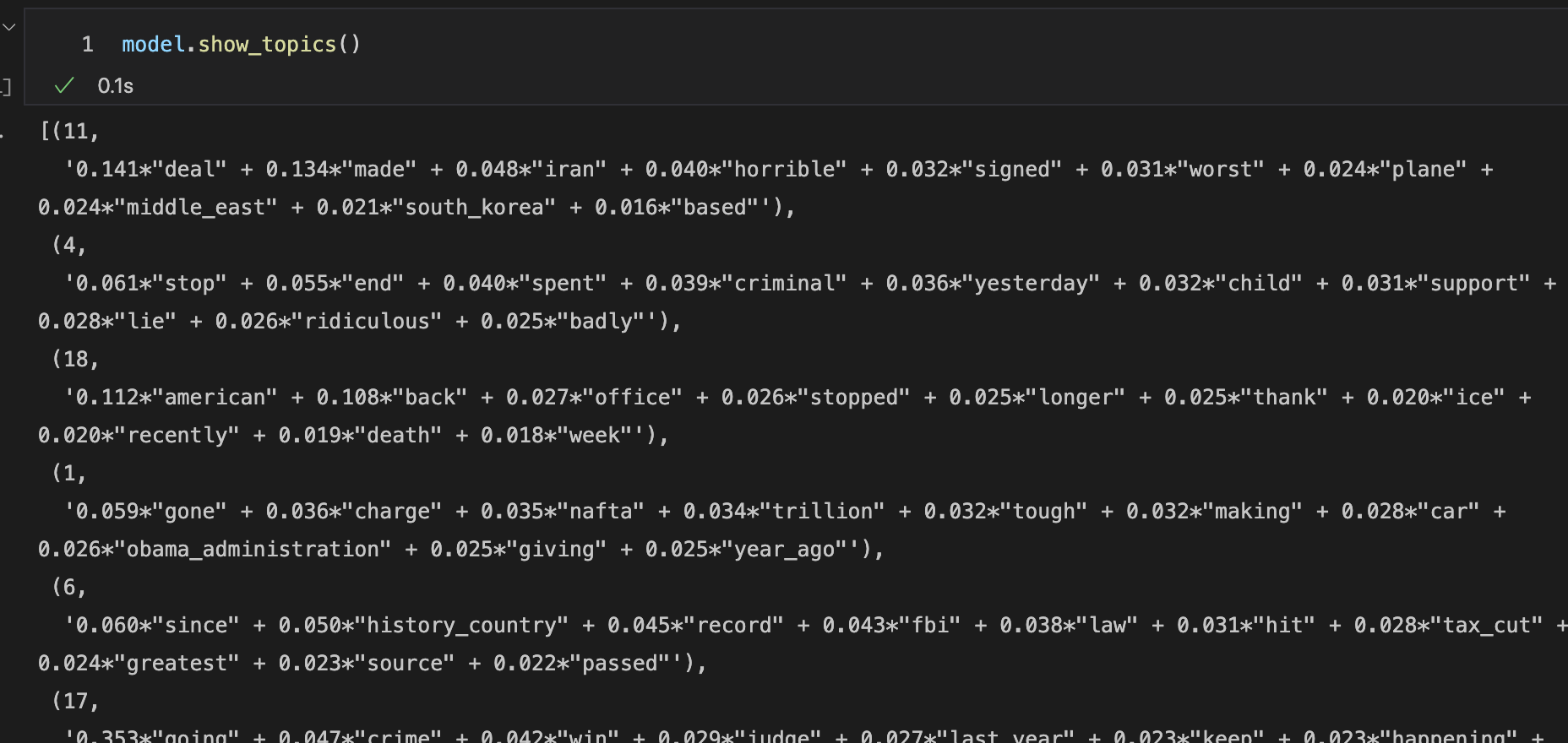
Latent Dirichlet Allocation (LDA) is a way of extracting latent, or hidden, topics from a set of documents. LDA assumes that documents are composed of a set of topics sampled from a probability distribution, and topics are composed of words sampled from a probability distribution. It is important to note that LDA does not choose the number of topics for you, nor does it label the topics; labelling topics is up to you based on the most frequent words in the topic.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | |
Using model.show_topics() we can see which tokens are used to determine the topics (note that the topics are identified by integers).
A LDA model performance is typically measured based on its Coherence Score.
1 2 3 | |
The above model has a score of
1 | |
but what does it mean? For this dataset we have topic already specified in column category. Lets compare our generated topics against these. First we need to set the topic for each document (claim) in our dataset. To do this I use the following function which select to mst likely topic for a given document
1 2 3 4 5 6 | |
Now a crosstab of given topic label category and predicted topic number topic should give us a nice clean table with only one non-zeros value in each row and in each column (i.e. a permutation of a diagonal matrix) ...
NOTE: When generating the steps for the practical I see now that I left in the 169 claims with missing category. Don't have time to fix this. So ignore this row. Sorry.
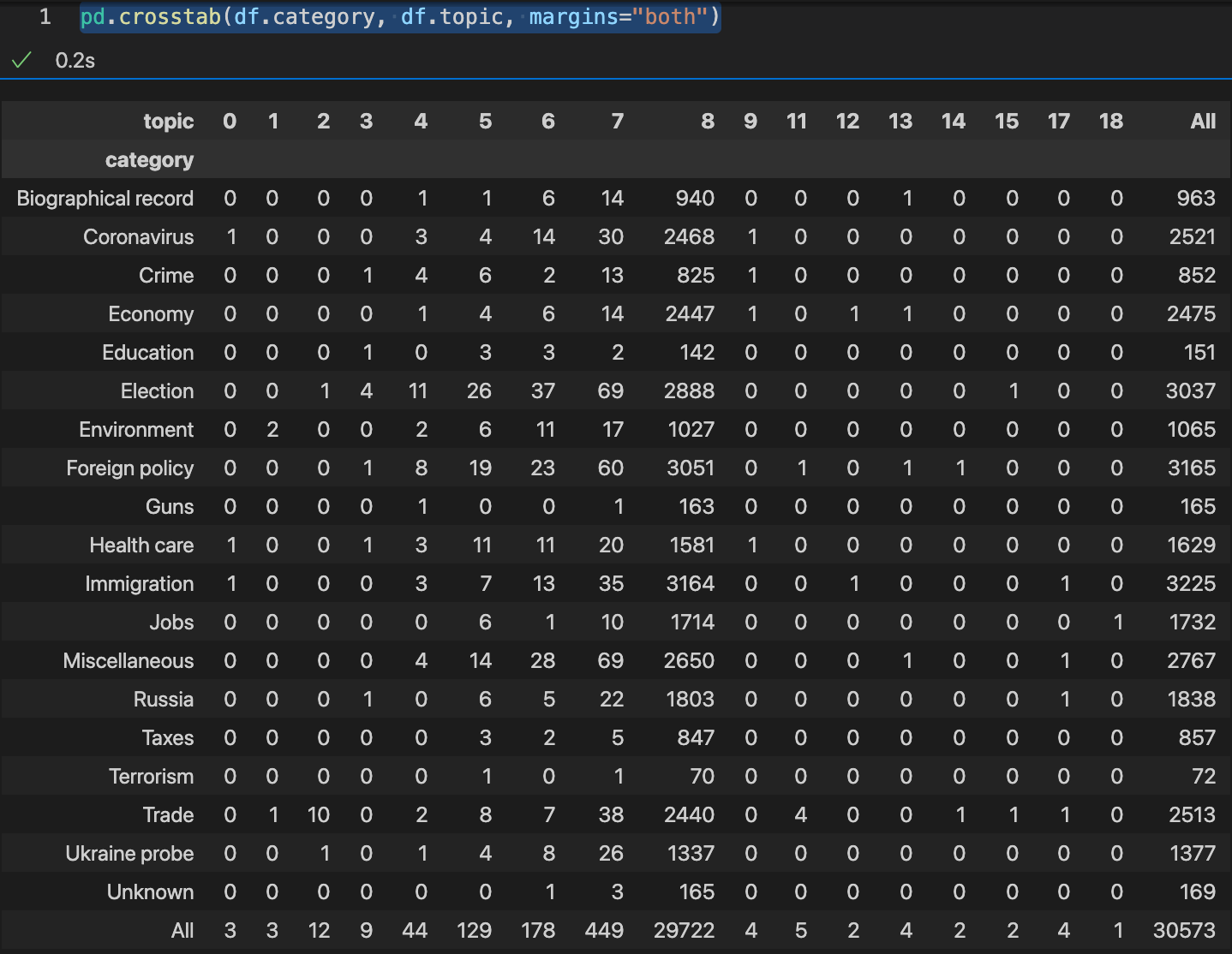
Well ... this is disappointing ... it seems that the topic modeling was throwing everything into topic 8. Can we do better? In the words of Obama, "Yes We Can".
This is easily improved by:
Since LDA does not determine the number of topics we could follow our standard procedure and perform a parameter sweep and select the number of topics that maxamised coherence score. We won't do this here since it will take too long (30 min) and we know that the number of topics should be 18.
There is an excellent library for interactively visualising output from a LDA.
Import using
1 2 3 4 5 6 | |
and create/open visualisation using
1 2 | |
For time reasons I won't cover this, but see resources at the start of this practical.