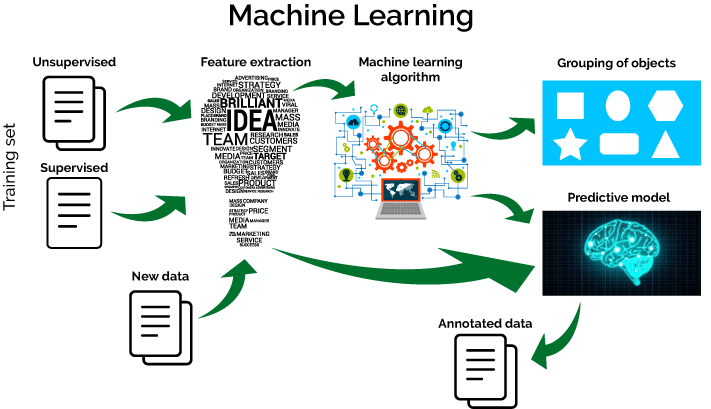
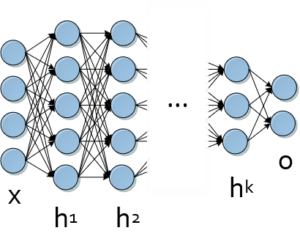
Since this modules is a continuation of the Data Mining 1 module of last semester, we will start with a quick review of what you have covered to date and what we will be doing this semester.
Last semester you learnt some data preparation techniques, such as scaling and transformations. Now we will build on that by covering techniques to generate new features from existing features.
Hyperparameters tunning is an essential part of the machine learning process, but is time consuming. We will look at the standard techniques (Grid/Random search) and more advanced strategies using the Bayesian optimisation (hyperopt) libraries.