Create a section in your notebook called Text Preprocessing.
Finally we get to topic modelling part. The dataframe df_submissions has two text columns title and text.
I want to see if topic modelling based on data from title column matches topic modelling based on text column.
I'm making a big assumption here. Namely: for any two rows, the title should be in the same topic whenever the text are in the same topics.
If this assumption is true then:
Using column title as initial documents
title_tokens.title_tokens and store in column title_ngrams.title_model, using title_ngrams using num_topics=5.title_model and store in column title_topics.Using column text as initial documents
text_tokens.text_tokens and store in column text_ngrams.text_model, using text_ngrams using num_topics=5.text_model and store in column text_topics.Then a crosstab of df.title_topics and df.text_topics should have a single large count in each row and in each column.
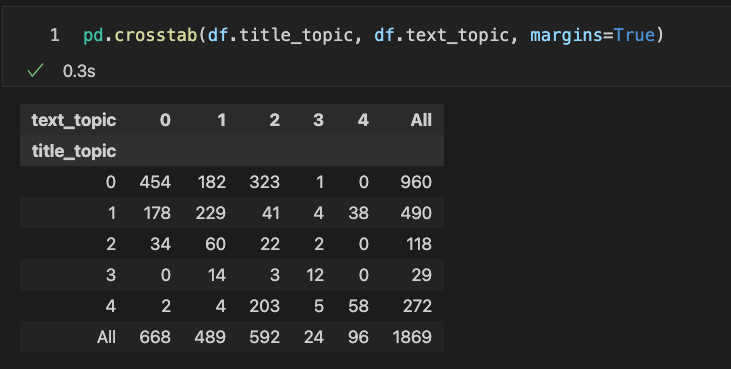
If we rearrange (permute) the rows/cols we might get a better alignment between title_topic and text_topic. This is a simple optimisation problem, which is implemented in the following function
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | |
Running this with verbose=True we get output
1 2 3 4 5 6 7 8 | |
All of the code to train the models is given in the trump false claims practical. But the following might be of use:
To speed up model fitting replace LdaModel by LdaMulticore but then you need to remove the alpha keyword argument (since that is not supported by LdaMulticore).
To see the list of words used in each topic run
1 2 | |
extra_stopwords, in the hope of improving the topic alignment.Assuming num_topics=5 and using LDA model LdaMulticore (or LdaModel if your computer does not support LdaMulticore) optimise the topic alignment between title and text by:
default_stopwords and extending extra_stopwords.