This is a small (<30 lines of code) text (or filename) cleaning task requiring the use of regex or/and fuzzy pattern matching.
In last year's Data Mining 2 class I asked students to submit two files as part of a particular assignment. The files were to be named 01-Clean.ipynb and 02-Model.ipynb.
Like all students — except you of course — they decided to ignore the instructions and do their own thing and use different file names or some even decided to "help" by compressing files :-).
So I had to write code to redress this situation, and want you to go through the same pain.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | |
Parse this tree to produce dataframe similar to that shown below
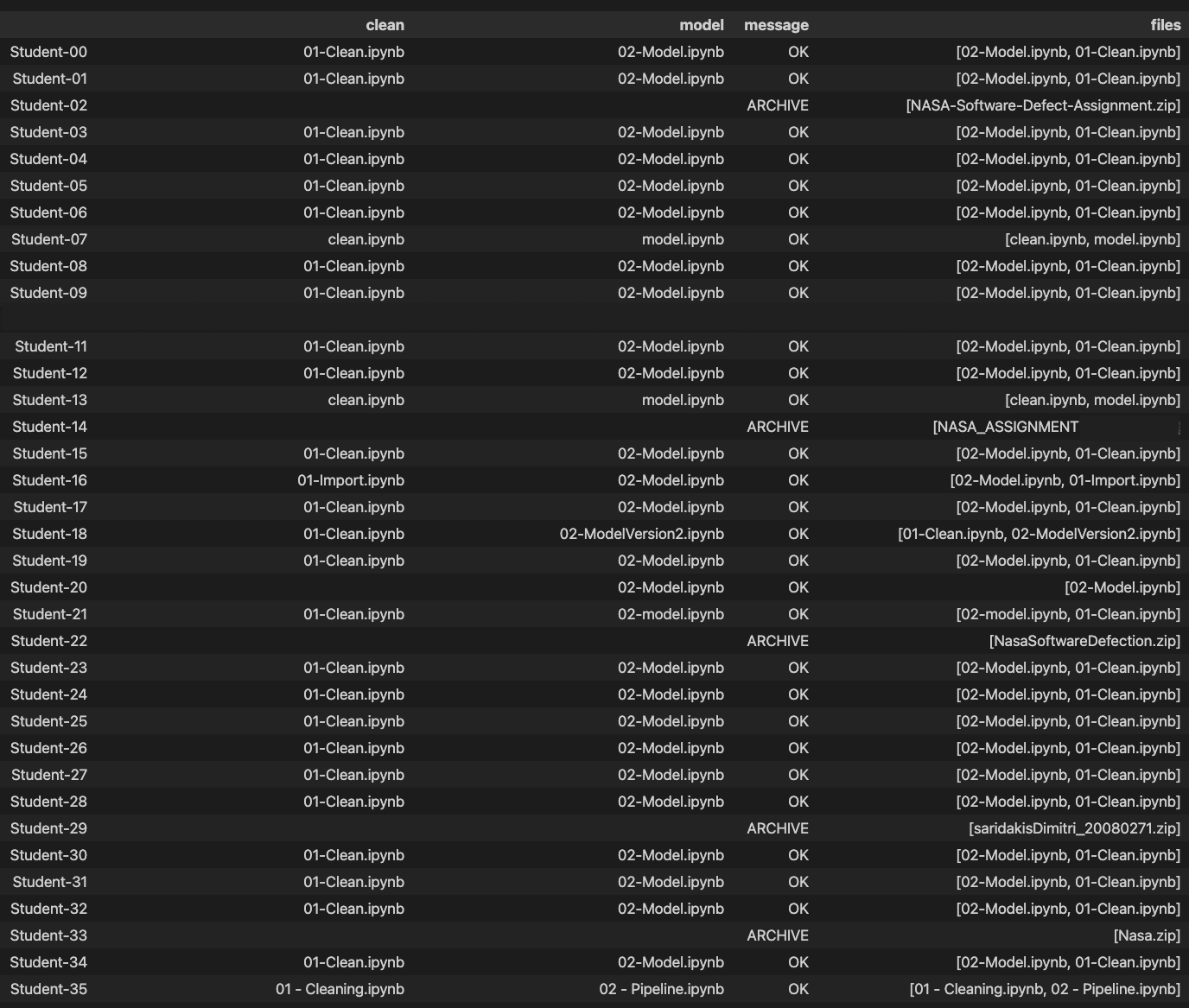
Where:
01-Clean.ipynb and which file should have been called 02-Model.ipynb. Use regex or fuzzy matching for this - NOT exact string matching! Aim for a generic matching as possible, i.e., considers next year's class - who are going to listen to me even less - and have other/more variations.
In the generated dataframe:
clean and model store matched filename or, if unmatched store empty string.message stores one of the following values (conditions tested in given order):ARCHIVE if an archive (bz2, gz, rar, zip, 7z) was uploaded.OK if the two uploaded files names matched given specification (including case), or uploaded files have been identified.UNKNOWN if there is a file that cannot be assigned.